Automation for Podbean Podcast Analytics
I am responsible for producing, editing, and analyzing sermons for my church. One of the questions I wanted to clarify is how quickly sermons(podcasts) fall or rise in rank in relation to other podcasts. There is no straightforward way of doing this within the simple analytics platform. And this is where the problem solving begins.
End Goal: To automatically capture ranking data at regularly set intervals for analysis later.
Example of Output:
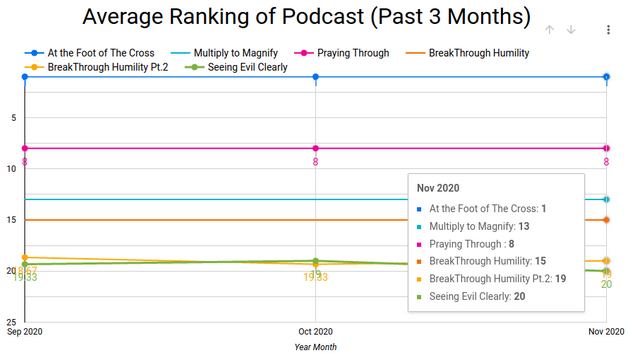
(Made with Google Data Studio)
Step One: Assessing the defaults
By default, Podbean limits users to only view the top 10 downloaded podcasts for any given period. Users can download this in a CSV. However, the whole process takes multiple clicks, and the information is limited.
Podbean does offer an API. However, upon signing up for a developer account and connecting to the API, I realized that that version of the API is no longer supported.
Step Two: Accessing the Podbean API
Part A: Downloading data with a Podbean API
As an SEO analyst, I have dabbled a lot with browser developer tools and figured I could get the request headers for the most downloaded episodes through the browser’s inspector network monitor.
Request Header:
GET /admin/stats/top-download-episodes?slug=thepathchurch&access-token=xxx&start=&end=&period=m&limit=10&t=5fa4bc7b&s=%2B96JsgOp3LIMR5crC60hCNkr6NQ%3D HTTP/1.1
Host: api-v2.podbean.com
User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:82.0) Gecko/20100101 Firefox/82.0
Accept: application/json, text/plain, */*
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
Origin: https://admin5.podbean.com
Connection: keep-alive
Referer: https://admin5.podbean.com/thepathchurch/stats/episodes
Let’s break down the GET request URL parameters:
- Slug: webpage identifier
- Access-token: Unique Access token that identifies users(refreshes every session). The fact it refreshes every session became a major issue to solve in the next part
- Start: Start Date
- End: End Date
- Period: the time unit (Month(m)/Day(d)/Year(y))
- Limit: The number of podbean episodes to display
- t/s: Not sure what these parameters do
Part B: Using Selenium and BrowserMob Proxy
Getting the response is straightforward, using Python’s request module. However, as stated in the last section, I had no way of generating an access token because I’m using version 2 of the API unofficially. I had already written the code to tap into the Podbean API but had no idea how to automate the process.
I knew I could automate the browser using Selenium. Even if I logged in automatically, I would still have a difficult time accessing browser developer tools. Selenium is primarily used for automated user testing. Through some research, I found BrowserMob Proxy (BrowserMob Proxy allows you to manipulate HTTP requests and responses, capture HTTP content, and export performance data as a HAR file.).
Once I got BrowserMob Proxy up and running, I used it to generate a HAR file then use regular expressions to get the sessions’ access-token.
Step Three: Uploading Data To Google Sheets & Clean-Up
Uploading the data Google Sheets was pretty straight forward. I authenticate myself with Google, open the target Google Sheet then append the generated csv to my Google Sheet.
`def uploadData():`
#GOOGLE AUTH STUFF
scope = ["https://spreadsheets.google.com/feeds", 'https://www.googleapis.com/auth/spreadsheets',
"https://www.googleapis.com/auth/drive.file", "https://www.googleapis.com/auth/drive"]
credentials = ServiceAccountCredentials.from_json_keyfile_name('/home/julius/Documents/programming/python/projects/Podbean_Analytics/client_secret.json', scope)
client = gspread.authorize(credentials)
files = os.listdir('google_sheets_top')
filtered_files = [file for file in files if file.endswith(".csv")]
#OPENS TARGET GOOGLE SHEET
spreadsheet = client.open('Copy of PodBean Stats')
sheet = spreadsheet.sheet1
#APPENDS LATEST DATA
with open(f'google_sheets_top/{filtered_files[0]}', newline='') as f:
reader = csv.reader(f)
data = list(reader)
sheet.append_rows(data[1:], value_input_option='USER_ENTERED', insert_data_option='INSERT_ROWS')
Conclusion:
It was a great project to take my automation skills to the next level and implement real problem solving for an organization. The final flow of the script:
- Initiate Selenium with BrowserMob Proxy to log into Podbean and get access token through regex
- I leave the connection open long enough for step 2 to occur
- Access Token is used to make a GET request for the top podcast, and that data is written into a CSV file
- I then add the DateTime and podcast rank using Pandas to the CSV for easier analysis
- The resulting CSV is uploaded to Google Sheets and then deleted locally.